Odczytywanie pliku: plik get content function (PHP)
Formalnie plik dostaje zawartość Konstrukcja PHP jest podobna do pliku, ale umieszcza treść odczytu w łańcuchu, a nie w tablicy łańcuchów, i pozwala określić przesunięcie w pliku, z którego rozpocznie się czytanie.
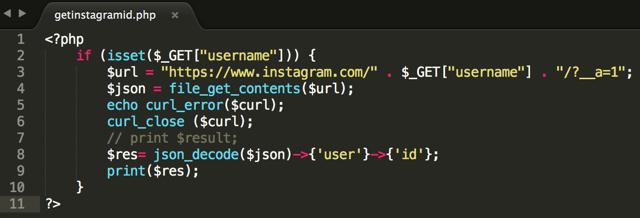
Regularne czytanie przez fopen / fgets / fclose staje się mniej istotne. Wygodniej jest odczytać zawartość całego pliku lub strony witryny, a następnie wykonać niezbędne operacje. Plik PHP umożliwia tworzenie treści umożliwia tworzenie bardziej wydajnych i wydajnych algorytmów. przetwarzanie informacji.
Składnia i przykład użycia
Składnia:

Tutaj $ filename to nazwa pliku lub URL strony, $ use_include_path pozwala na wyszukanie pliku w ścieżce dołączania, $ context jest zasobem utworzonym przez konstrukcję stream_context_create (), $ offset jest przesunięciem do rozpoczęcia czytania, $ maxlen jest maksymalną ilością danych do odczytania .
Zwykle używa się prostszego pliku PHP, który pobiera treść:
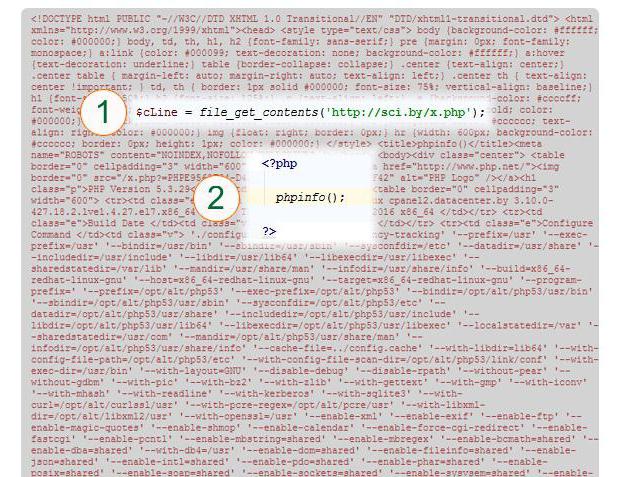 W tym przykładzie treść strony jest odczytywana do zmiennej $ cLine (1). Podany adres URL jest wskazany. W rzeczywistości strona (2) jest reprezentowana przez konstrukcję PHP phpinfo (), czyli nie jest tekstem trzech linii, które są odczytywane, ale wynikiem wykonania tej funkcji.
W tym przykładzie treść strony jest odczytywana do zmiennej $ cLine (1). Podany adres URL jest wskazany. W rzeczywistości strona (2) jest reprezentowana przez konstrukcję PHP phpinfo (), czyli nie jest tekstem trzech linii, które są odczytywane, ale wynikiem wykonania tej funkcji.
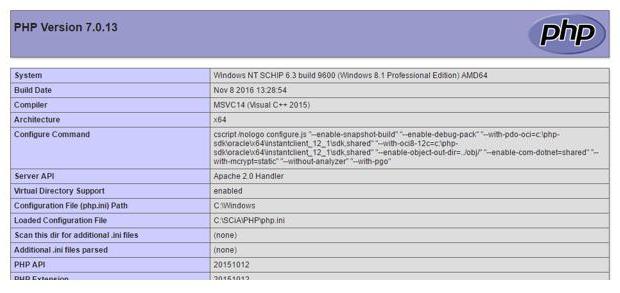
Jak widać, wynikiem jest pełnowartościowa strona, podczas gdy plik PHP pobiera zawartość konstruuje w (http ...) czyta i zapisuje wewnętrzną zawartość tej strony w zmiennej $ cLine.
Opcje kontekstowe i opcje
Należy pamiętać, że użycie parametru $ context otwiera ogromne możliwości.

W normalnej praktyce użycie wszystkich parametrów oprócz $ filename nie jest popularną regułą. Jednak wartość tworzona przez konstruktę stream_context_create () i używana jako parametr kontekstu $ umożliwia pisanie dość złożonych algorytmów w celu uzyskania niezbędnych informacji.
Różne systemy plików, programy do obsługi strumienia (owijki) wymagają różnych parametrów i opcji do opisania kontekstu. Można go utworzyć poprzez konstrukcje stream_context_create (stream_context_set_option, stream_context_set_params).
Przetwarzanie masowej strony
Zamiast konkretnego Adresy URL Parametr $ filename może być reprezentowany przez nazwę zmiennej. Umożliwia to analizę zawartości stron w trybie automatycznym programowalnym, rozpoznawanie nazw stron, ustalanie linków, wyciąganie niezbędnych informacji.
Możesz stworzyć własny parser witryny, wyszukiwarkę i pisać programy do rozproszonego przetwarzania informacji. Zadanie jest istotne, interesujące i praktyczne.
Czytanie plików tekstowych
Nie ma problemów, które plik do odczytania. W poniższej, złożonej wersji, budowanie zawartości pliku php jest przykładem tego, że plik "Word" można odczytać bez problemów:

Oto złożony dokument, który służy do testowania biblioteki PHPOffice / PHPWord. Plik MS Word (* .docx), jak wiecie, jest archiwum zip, wewnątrz którego znajdują się informacje na temat standardu Open XML.
Z reguły pliki dokumentów są dość duże i skomplikowane, ale plik PHP jest gotowy do konstruowania treści i radzi sobie z ich łatwością czytania. Specyfika tego konkretnego przykładu polega na tym, że przetwarzanie dokumentu przy użyciu wyłącznie biblioteki PHPOffice / PHPWord nie zapewnia niezbędnych funkcji, a po prostu niemożliwe jest odczytanie pliku sekwencyjnie.
W tym dokumencie wszystkie jego elementy (słowa, akapity, formuły, obrazy, elementy pisowni) są opisane przez serię znaczników, z których niektóre mogą być reprezentowane przez sekwencję obiektów zagnieżdżonych w sobie.
Jeśli weźmiesz przykład dokumentu (* .docx) razem z tabelami, sytuacja nie zostanie rozwiązana w ogóle przy sekwencyjnym przetwarzaniu pliku. Wymaga co najmniej dwóch przejść przez treść dokumentu, jeśli nie w szczególności, na przykład, gdy tabele gniazdują jeden na drugim.
Kodowanie i specjalne problemy z postaciami
Jeśli czytanie złożonych plików nie powoduje problemów, to problemy z pracą z prostymi plikami. Początkowo powinno to być aksjomatem: PHP odczytuje plik, aby uzyskać prawidłową konstrukcję zawartości. Nawet jeśli nie użyjesz pewnych parametrów, najprostsza wersja aplikacji zawsze będzie działać tak, jak powinna.
Trudności spowodowane są nawiasami ostrymi i kodowaniem plików. Konieczne jest rozróżnienie pracy wewnątrz algorytmu od wyświetlenia wyniku w oknie przeglądarki. Na rysunku z przykładem pliku Word, wiersz (1) - $ cLine = scChangeLTGT ($ cLine) - wywołuje funkcję konwersji pary nawiasów trójkątnych na znaki specjalne "<" i ">", w przeciwnym razie plik odczytu nie zawsze może być wyświetlany w oknie przeglądarki. Jak napisać tę funkcję nie jest ważne, ale ważne jest, aby nie zapomnieć, że odczytane informacje mogą zawierać znaczniki XML i HTML, a to wymaga szczególnej uwagi.
Następny punkt: kodowanie plików. Nie zawsze prosty plik tekstowy nie stwarza problemów. Jeżeli czytane są informacje tekstowe, obecność rosyjskich liter może stwarzać pewne trudności (2).
$ cLine = iconv ('UTF-8', 'CP1251', $ cLine). W tym kontekście użycie funkcji iconv () z właściwym kierunkiem konwersji jest istotne nie tylko w odniesieniu do PHP "file get contents http://" do czytania strony witryny, ale także do odczytu zwykłego pliku lokalnego.
Jeśli wynik odczytu jest "niewidoczny", najpierw należy sprawdzić kodowanie znaków.