Replikacja jest czym?
Dzisiaj porozmawiamy o tym, czym jest replikacja danych. Jak się go używa? Jakie typy istnieją? Pomimo tego, że termin ten najczęściej spotyka się w sferze komputerowej, oznacza on także pewne procesy zachodzące nawet w przeciwnych dziedzinach nauki. Zobaczmy replikację - co to jest?
Pochodzenie
Sam termin pochodzi z łaciny, od słowa replicatio - odnowienie, powtórzenie. Możemy zatem stwierdzić, że współczesna koncepcja replikacji oznacza z grubsza to samo - zwiększenie liczby, kopiowanie. Replikacja to proces, który umożliwia utworzenie kopii obiektu.
Zacznijmy od prostszych koncepcji. Proces replikacji płyt CD polega w istocie na replikacji i dystrybucji ze względu na wzrost produkcji, a tym samym na ilość stempli produkowanych przez zakład.
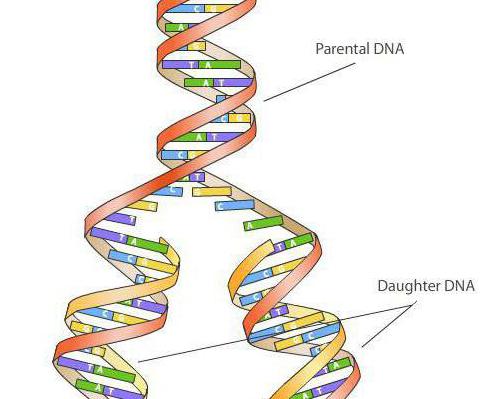
W medycynie i biologii replikacja jest procesem, który jest podstawą podział komórek, co powoduje podwojenie Cząsteczki DNA. Z tego powodu istnieje pełne kopiowanie materiału genetycznego do transmisji z pokolenia na pokolenie.
ICT
W środowisku komputerowym replikacja jest jednym z powodów, dla których administratorzy systemu mogą spać spokojnie. Ten proces jest bardzo podobny do tworzenia kopii zapasowych danych serwera, ale w rzeczywistości jest tylko jego częścią. Można wyróżnić dwa typy replikacji - synchroniczne i asynchroniczne. Jaka jest esencja tego procesu?

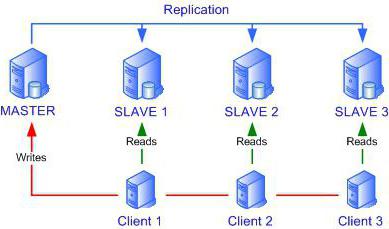
Replikacja to technika skalowania baz danych. Polega ona na tym, że dane z głównego serwera ("master") są w sposób ciągły kopiowane do jednego lub kilku drugorzędnych ("slave"). W rezultacie aplikacje klienckie mogą wykorzystywać dane nie z jednego węzła sieci, ale z kilku, co z kolei znacznie zmniejsza obciążenie.
Klasyfikacja
Stosowane są dwa typy replikacji. Pierwszym z nich jest replikacja jako master slave. Schemat ten wykorzystuje zasadę, że wszystkie zmiany występują tylko na jednym serwerze - "master". A potem są kopiowane do replikacji serwerów - niewolników. Zatem każdy z nich spełnia swoją funkcję.
- Jeśli zachodzi potrzeba wprowadzenia zmian na serwerze (zapis, usunięcie, aktualizacja danych), program odwołuje się do "master".
- Jeśli potrzebujesz tylko próbki danych (odczyt), zostaną one pobrane z dowolnego z serwerów pomocniczych.
Ten schemat jest dość wygodny. W przypadku problemów na "master", wszystkie operacje zapisu muszą być przełączone na "slave", odwrotne jest również prawdziwe. Serwery są całkowicie wymienne. Podczas korzystania z tego typu replikacji można umieścić do 20 serwerów "slave". Często ten typ służy do tworzenia kopii zapasowych danych.
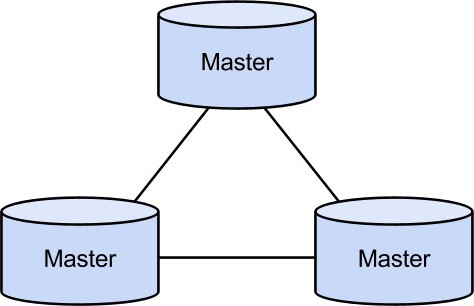
Drugim typem replikacji jest "master master". Oznacza to, że użytkownik uzyskuje dostęp do losowego serwera, a następnie wymienia dane między sobą. Schemat ten jest bardzo nieatrakcyjny z punktu widzenia bezpieczeństwa, ponieważ w przypadku awarii jednego z serwerów, w większości przypadków dane są tracone.
Asynchrony
Pomimo wszystkich zalet tej techniki, replikacja SQL ma kilka wad. Jednym z nich są operacje asynchroniczne. Oznacza to, że istnieje opóźnienie w przeniesieniu z serwera głównego do "urządzenia podrzędnego". Trudno jest określić, jak szybko nowe dane pojawią się na "slave", ponieważ opóźnienie może być dość nieznaczne, a może bardzo duże. Jeśli potrzebujesz ciągłej pracy z danymi, musisz użyć połączenia z tym samym serwerem "głównym" i nie odczytać danych z "slave".
Aby tego uniknąć, możesz użyć trybu synchronicznego. Zasada jest taka, że wszystkie żądania przychodzą na serwer główny, a odpowiedzi pochodzą od "niewolnika". W ten sposób gwarantowane jest pełne kopiowanie danych do węzła drugorzędnego. Oczywiście prowadzi to do dużej utraty prędkości, ale upraszcza cały system.
Ręcznie
Ponieważ replikacja jest złożonym i wieloaspektowym procesem, bardzo trudno jest uwzględnić wszystkie aspekty tej metodologii. Ponadto nie jest to konkretna technologia, ale raczej zestaw konkretnych instrukcji i działań. Co więcej, niektóre technologie komputerowe nie są w stanie pracować z replikacją w zasadzie.
W takich sytuacjach istnieje specjalna technika. Podczas tworzenia aplikacji można dodać autoreplikację. Twoja aplikacja musi wysyłać żądania do kilku serwerów jednocześnie, aby uniknąć problemów związanych z replikacją i ominąć jej brak między serwerami, uzyskując wszystkie niezbędne dane.
W przypadku awarii jednego z serwerów, konieczne jest wyłączenie niedziałającego serwera i włączenie replikacji według typu - "master slave". Umożliwi to synchronizację wszystkich replik i porządkowanie danych. Po naprawieniu uszkodzonego serwera i synchronizacji, możesz go ponownie włączyć do systemu i przywrócić wszystko do normalności.
Wynik
Wykorzystanie replikacji w systemach baz danych nie zawsze jest uzasadnione. Skomplikowane mechanizmy odczytu zapisu zmniejszają szybkość przetwarzania żądań lub zmniejszają niezawodność systemu. przetwarzanie informacji. Tak więc, jeśli potrzebujesz stworzyć kopię zapasową swojego działającego serwera, regularnie rób to sam lepiej i śpij spokojnie.