Kodowanie ASCII. Tabela kodowania ASCII
Pod informacje o kodowaniu w komputerze rozumie się proces jego przekształcenia w formę, która umożliwia zorganizowanie wygodniejszego transferu, przechowywania lub automatycznego przetwarzania tych danych. W tym celu wykorzystywane są różne tabele. Kodowanie ASCII to pierwszy system opracowany w Stanach Zjednoczonych do pracy z tekstem w języku angielskim, który następnie został rozpowszechniony na całym świecie. Jego opis, cechy, właściwości i dalsze wykorzystanie tego artykułu przedstawiono poniżej.
Wyświetlanie i przechowywanie informacji w komputerze
Symbole na monitorze komputera lub mobilnym gadżecie cyfrowym są tworzone na podstawie zestawów wektorów o różnych znakach i kodzie, co pozwala znaleźć wśród nich postać, którą należy wstawić we właściwe miejsce. Jest to sekwencja bitów. Zatem każdy symbol musi jednoznacznie odpowiadać zestawowi zer i jedynek, które znajdują się w określonej, unikalnej kolejności.
Ad
Jak to się wszystko zaczęło
Historycznie pierwsze komputery były anglojęzyczne. Do zakodowania w nich informacji symbolicznej wystarczyło użyć tylko 7 bitów pamięci, podczas gdy w tym celu przydzielono 1 bajt składający się z 8 bitów. Liczba znaków rozumianych przez komputer w tym przypadku wynosiła 128. Znaki te obejmowały alfabet angielski z jego znakami interpunkcyjnymi, liczbami i niektórymi znaki specjalne. Angielskie siedmiobitowe kodowanie z odpowiednią tabelą (stroną kodową), opracowane w 1963 r., Nosiło nazwę American Standard Code for Information Interchange. Zwykle do jego oznaczenia używano skrótu "Kodowanie ASCII" i jest on nadal używany.
Ad
Przejście do wielojęzyczności
Z biegiem czasu komputery zaczęły być szeroko stosowane w krajach nieanglojęzycznych. W związku z tym istnieje potrzeba kodowania, które pozwala na używanie języków narodowych. Postanowiono nie odkrywać koła na nowo i brać ASCII za podstawę. Tabela kodowania w nowym wydaniu znacznie się rozszerzyła. Użycie ósmego bitu pozwoliło na przetłumaczenie 256 znaków na język komputerowy.
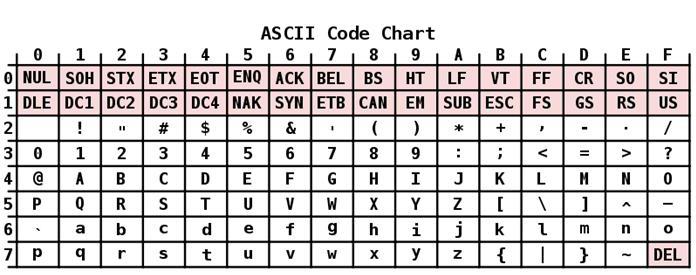
Opis
Kodowanie ASCII ma tabelę podzieloną na 2 części. Za ogólnie przyjętą normę międzynarodową uważa się tylko jej pierwszą połowę. Obejmuje:
- Znaki o numerach sekwencji od 0 do 31, kodowane za pomocą sekwencji od 00000000 do 00011111. Są zarezerwowane dla znaków sterujących, które kontrolują proces wyświetlania tekstu na ekranie lub drukarce, sygnał dźwiękowy itp.
- Znaki z NN w tabeli od 32 do 127, kodowane przez sekwencje od 00100000 do 01111111 stanowią standardową część tabeli. Należą do nich spacja (N 32), litery łacińskie (małe i wielkie litery), dziesięciocyfrowe liczby od 0 do 9, znaki interpunkcyjne, nawiasy różnego typu i inne znaki.
- Znaki o numerach sekwencji od 128 do 255, kodowane sekwencjami od 10 000 000 do 1111 1111. Obejmują litery alfabetów narodowych innych niż łaciński. Ta alternatywna część tabeli to kodowanie ASCII używane do konwersji rosyjskich znaków na postać komputerową.
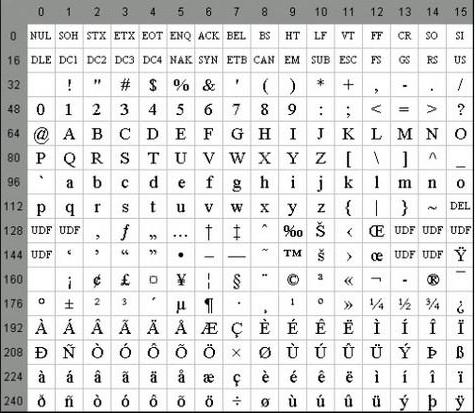
Niektóre właściwości
Szczególne cechy kodowania ASCII to różnica między literami "A" - "Z" dolnego i górnego rejestru z tylko jednym bitem. Ta okoliczność znacznie upraszcza konwersję rejestru, a także weryfikację przynależności do danego zakresu wartości. Ponadto, wszystkie litery w systemie kodowania ASCII są reprezentowane przez ich własne numery seryjne w alfabecie, które są zapisane 5 cyframi w systemie liczb dwójkowych, przed którym dla małych liter wynosi 011 2 , a górne jest 010 2 .
Ad
Wśród funkcji kodowania ASCII można policzyć i prezentacji 10 cyfr - "0" - "9". W drugim systemie liczbowym zaczynają się od 00112, a kończą na 2 liczbach. Tak więc, 0101 2 jest równoważny liczbie dziesiętnej pięciu, więc znak "5" jest zapisany jako 0011 01012. W oparciu o powyższe, możesz łatwo konwertować liczby dziesiętne binarne na ciąg znaków w ASCII, dodając sekwencję bitów 00112 do każdego półbajtu w lewo.

"Unicode"
Jak wiadomo, tysiące znaków są wymagane do wyświetlania tekstów w językach grupy Azji Południowo-Wschodniej. Taka ich liczba nie jest opisana w żaden sposób w jednym bajcie informacji, dlatego nawet rozszerzone wersje ASCII nie mogły już zaspokoić rosnących potrzeb użytkowników z różnych krajów.
Stąd stało się konieczne stworzenie uniwersalnego kodowania tekstu, którego rozwój, we współpracy z wieloma liderami światowej branży IT, został podjęty przez konsorcjum Unicode. Jego specjaliści stworzyli system UTF 32. W nim przydzielono 32 bity do zakodowania 1 znaku, co stanowiło 4 bajty informacji. Główną wadą był gwałtowny wzrost ilości wymaganej pamięci aż czterokrotnie, co wiązało się z wieloma problemami.
Ad
W tym samym czasie, dla większości krajów z oficjalnymi językami należącymi do grupy indoeuropejskiej, liczba znaków równa 2 32 jest więcej niż zbędna.
W wyniku dalszej pracy specjalistów z konsorcjum Unicode pojawiło się kodowanie UTF-16. Stała się opcją konwertowania informacji symbolicznych, które zaaranżowały dla każdego zarówno pod względem ilości wymaganej pamięci, jak i liczby zakodowanych znaków. Z tego powodu UTF-16 został przyjęty domyślnie i wymaga zarezerwowania 2 bajtów dla jednego znaku.
Nawet ta dość zaawansowana i udana wersja Unicode miała pewne wady, a po zmianie z rozszerzonej wersji ASCII na UTF-16 podwajała wagę dokumentu.
W związku z tym zdecydowano się na użycie kodowania o zmiennej długości UTF-8. W tym przypadku każdy znak w tekście źródłowym jest kodowany w sekwencji od 1 do 6 bajtów długości.

Skontaktuj się z amerykańskim standardowym kodem do wymiany informacji
Wszystkie znaki alfabet łaciński w zmiennej długości UTF-8 zakodowanej w 1 bajcie, tak jak w systemie kodowania ASCII.
Szczególną cechą UTF-8 jest to, że w przypadku tekstu w języku łacińskim bez użycia innych znaków, nawet programy, które nie rozumieją Unicodu, nadal będą zezwalać na jego odczytanie. Innymi słowy, podstawowa część kodowania tekstu ASCII jest po prostu przenoszona do nowej długości zmiennej UTF. Znaki cyrylicy w UTF-8 zajmują 2 bajty i, na przykład, gruziński - 3 bajty. Tworząc UTF-16 i 8, rozwiązano główny problem tworzenia pojedynczej przestrzeni kodu w czcionkach. Od tego czasu producenci czcionek muszą wypełniać tabelę jedynie wektorowymi symbolami symboli tekstowych w oparciu o ich potrzeby.
Ad
W różnych systemach operacyjnych preferowane są różne kodowania. Aby móc czytać i edytować teksty wpisane w innym kodowaniu, używane są rosyjskie programy konwersji tekstu. Niektóre edytory tekstu zawierają osadzone transkodery i umożliwiają czytanie tekstu bez względu na kodowanie.

Teraz wiesz, ile znaków jest w ASCII i jak i dlaczego został opracowany. Oczywiście dzisiaj standard Unicode stał się najbardziej rozpowszechniony na świecie. Jednak nie wolno nam zapominać, że został stworzony na podstawie ASCII, więc należy docenić wkład jego twórców w dziedzinie IT.