Protokoły ARP, RARP, ICMP: zasada działania, cel
Jeśli komputer kontaktuje się z innym podobnym urządzeniem w tej samej sieci, wymagany jest adres fizyczny lub adres MAC. Ale ponieważ aplikacja podała adres IP odbiorcy, potrzebuje jakiegoś mechanizmu, aby powiązać go z adresem MAC. Odbywa się to za pomocą protokołu ARP (Address Resolution Protocol). Adres IP węzła docelowego jest nadawany, a węzeł odbiorczy zgłasza źródło swojego adresu MAC.
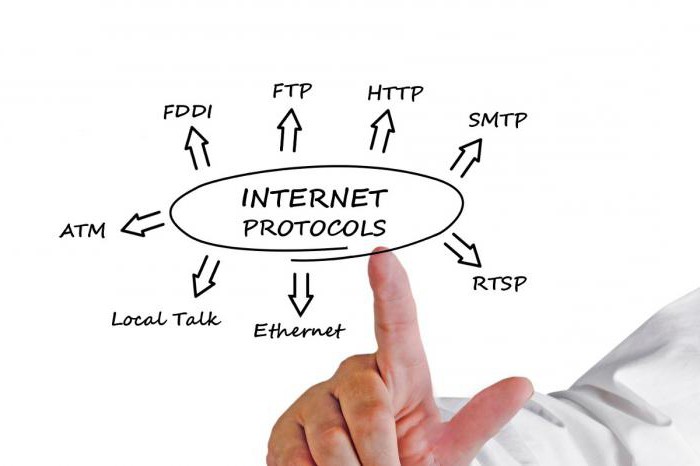
Oznacza to, że w każdym przypadku, gdy maszyna A zamierza przesłać pakiety danych do urządzenia B, musi wysłać pakiet ARP w celu rozpoznania adresu MAC B. W związku z tym zwiększa to obciążenie przesyłu zbyt wiele, w związku z tym, w celu zmniejszenia kosztów komunikacji, komputerów, które używają protokołów ARP, przechowują pamięć podręczną nowo uzyskanych wiązań adresów IP_to_MAC, tj. nie powinni ponownie używać tego protokołu.
Nowoczesny wygląd
Dziś wprowadzono kilka ulepszeń do protokołu ARP i jego celu. Tak więc, gdy maszyna A chce wysłać pakiety do urządzenia B, możliwe jest, że B wkrótce wyśle dane dla A. Z tego powodu, aby uniknąć ARP dla komputera B, A musi powiązać adres IP_to_MAC, żądając adresu MAC B w specjalnym pakiecie.
Ponieważ A wysyła swoje początkowe żądanie adresu MAC B, każdy komputer w sieci musi wyodrębnić i zapisać powiązanie adresu IP_to_MAC w pamięci podręcznej.Jeśli nowy komputer pojawi się w sieci (na przykład, gdy system operacyjny zostanie zrestartowany), może nadać to powiązanie do wszystkie inne maszyny mogą przechowywać je w pamięciach podręcznych. To wyeliminuje wiele pakietów ARP ze wszystkimi innymi komputerami, gdy będą chcieli komunikować się z dodanym urządzeniem.

Odmiany protokołu ARP
Rozważmy scenariusz, w którym komputer próbuje komunikować się ze zdalnym komputerem przy użyciu programu PING, podczas gdy wcześniej nie było wymiany datagramów IP między tymi urządzeniami, a pakiet ARP musi zostać wysłany w celu zidentyfikowania adresu MAC zdalnego komputera.
Komunikat żądania Protokół Address Resolution (który wygląda jak wywołanie AAAA do BBBB - adresy IP) jest nadawany w sieci lokalnej przy użyciu protokołu Ethernet typu 0x806. Pakiet jest odrzucany przez wszystkie maszyny, z wyjątkiem celu, który odpowiada komunikatem odpowiedzi APR (AAAA - hh: hh: hh: hh: hh: hh, gdzie hh: hh: hh: hh: hh: hh jest adresem źródła Ethernet). Ta odpowiedź jest wysyłana pojedynczo do urządzenia z adresem IP BBBB Ponieważ komunikat żądania protokołu APR zawiera adres sprzętowy (mianowicie źródło Ethernet) komputera żądającego, urządzenie docelowe nie potrzebuje innego komunikatu, aby to zrozumieć.

Połączenie z innymi protokołami
Gdy zrozumiesz, do czego służy protokół ARP, powinieneś rozważyć jego interakcję z innymi elementami sieci.
RARP - to jest protokół za pośrednictwem której fizyczna maszyna w sieci lokalnej może wysyłać żądanie znalezienia swojego adresu IP z tabeli protokołów lub buforowania serwera bramy. Jest to konieczne, ponieważ trwale zainstalowany dysk nie może być obecny na urządzeniu, gdzie może trwale zapisać swój adres IP. Administrator sieci tworzy tabelę w routerze lokalnej bramy sieciowej, która mapuje adresy fizycznego komputera (lub kontroli dostępu MAC) do odpowiedniego adresu IP. Po skonfigurowaniu nowego komputera jego program klienta RARP żąda od serwera RARP na routerze, aby wysłał swój adres IP. Zakładając, że wpis został skonfigurowany w tabeli routera, ten serwer RARP zwróci "ip" na komputer, który może go zapisać do wykorzystania w przyszłości. Jest to więc również swoisty protokół ustalania adresu.
Mechanizm w szczegółach
Zarówno maszyna wysyłająca żądanie, jak i serwer odpowiadający na nie, używają fizycznych adresów sieciowych w procesie ich krótkiego połączenia. Zazwyczaj komputer żądający nie wie o tym. W ten sposób żądanie jest przesyłane do wszystkich komputerów w sieci. Żądający musi teraz zidentyfikować się w unikalny sposób na serwerze. W tym celu można użyć numeru seryjnego procesora lub fizycznego adresu sieciowego urządzenia. Użycie drugiego jako unikalnego identyfikatora ma dwie zalety:
- Te adresy są zawsze dostępne i niekoniecznie są powiązane z kodem rozruchowym.
- Ponieważ informacje identyfikacyjne zależą od sieci, a nie od procesora, wszystkie komputery w tej sieci będą dostarczać niepowtarzalne identyfikatory.
Podobnie jak wiadomość ARP, żądanie RARP jest wysyłane z jednego komputera do drugiego, obudowane w części danych ramki sieci. Zawierająca go ramka Ethernet zawiera typową preambułę, źródło Ethernet i adresy docelowe oraz pola typu pakietu przed ramką. Ramka koduje wartość 8035, aby zidentyfikować jej zawartość jako komunikat RARP. Część danych ramki zawiera komunikat 28-oktetowy.

Nadawca wysyła żądanie RARP, które identyfikuje się jako inicjator żądania i maszyna docelowa, i wysyła swój fizyczny adres sieciowy w docelowym polu adresu sprzętowego. Wszystkie urządzenia w sieci otrzymują żądanie, ale tylko ci, którzy są uprawnieni do dostarczania RARP, przetwarzają żądanie i wysyłają odpowiedź. Takie maszyny są znane nieformalnie jako serwery tego protokołu. Aby pomyślnie wdrożyć protokoły ARP / RARP, sieć musi zawierać co najmniej jeden taki serwer.
Odpowiadają na żądanie, wypełniając pole adresu docelowego protokołu, zmieniając typ komunikatu z żądania na odpowiedź i wysyłając odpowiedź bezpośrednio do urządzenia wysyłającego żądanie.
Synchronizacja transakcji RARP
Ponieważ RARP bezpośrednio korzysta z sieci fizycznej, żadne inne oprogramowanie protokołu nie może odpowiedzieć na to żądanie ani go retransmitować. RARP musi wykonywać te zadania. Niektóre stacje robocze korzystające z takiego protokołu do pobierania wolą ponawiać próbę w nieskończoność, dopóki nie otrzymają odpowiedzi. Inne implementacje deklarują awarię po kilku próbach uniemożliwienia wypełnienia niepotrzebnej transmisji.
Zalety serwerów Mulitple RARP: wysoka niezawodność.
Wada: przeciążenie może wystąpić, gdy wszystkie serwery odpowiadają.
Dlatego aby uniknąć wad, możesz korzystać z serwerów głównych i pomocniczych. Każdy komputer żądający żądania RARP ma przypisany serwer główny. Zwykle odpowiada na wszystkie wezwania, ale jeśli mu się nie uda, śledczy może przerwać i przesłać żądanie. Jeśli drugi serwer otrzyma drugą kopię żądania w krótkim czasie od pierwszego, odpowiada. Wciąż jednak może pojawić się problem polegający na domyślnym reagowaniu wszystkich serwerów pomocniczych, co powoduje przeciążenie sieci. Zatem problemem jest uniknięcie jednoczesnej transmisji odpowiedzi z obu serwerów. Każdy serwer pomocniczy, który odbiera żądanie, oblicza losowe opóźnienie, a następnie wysyła odpowiedź.

Wady RARP
Ponieważ działa na niskim poziomie, wymaga bezpośrednich adresów w sieci, co utrudnia aplikacjom tworzenie serwera. Nie wykorzystuje w pełni możliwości sieci takiej jak Ethernet, która służy do wysyłania pakietu minimalnego. Ponieważ odpowiedź serwera zawiera tylko jedną małą informację, 32-bitowy adres internetowy RARP jest formalnie opisany w RFC903.
Protokół ICMP
Protokół ten szyfruje mechanizm wykorzystywany przez bramki i hosty do wymiany informacji o zarządzaniu lub błędach. Protokół internetowy zapewnia niezawodną usługę bezpołączeniową, a datagram przenosi się z bramy do bramy, aż dotrze do tego, który może dostarczyć ją bezpośrednio do miejsca docelowego.
Jeśli brama nie może przekazać ani dostarczyć datagramu, lub jeśli wykryje nietypowy stan, taki jak przeciążenie sieci, które wpływa na możliwość przekierowania datagramu, musi zostać poinstruowany przez źródło, aby podjął działanie, aby uniknąć lub wyeliminować problem.
Link
Protokół kontroli protokołu internetowego umożliwia bramkom wysyłanie komunikatów o błędach lub zarządzanie wiadomościami do innych bram lub hostów. ICMP zapewnia komunikację między oprogramowaniem protokołu internetowego między komputerami. Jest to tak zwany mechanizm komunikatów specjalnego przeznaczenia dodawany przez programistów do protokołów TCP / IP. Dzięki temu bramki w Internecie mogą zgłaszać błędy lub wysyłać informacje o nieprzewidzianych okolicznościach.
Sam protokół IP nie zawiera niczego, co pomogłoby połączyć się z testowaniem nadawcy lub dowiedzieć się o błędach. Raporty o błędach i poprawki są zgłaszane przez ICMP tylko w odniesieniu do oryginalnego źródła. Musi wiązać błędy z poszczególnymi programami aplikacji i podejmować działania w celu rozwiązania problemów. Dzięki temu brama może zgłosić błąd. Nie określa jednak w pełni działań, które należy podjąć w celu rozwiązania problemu.
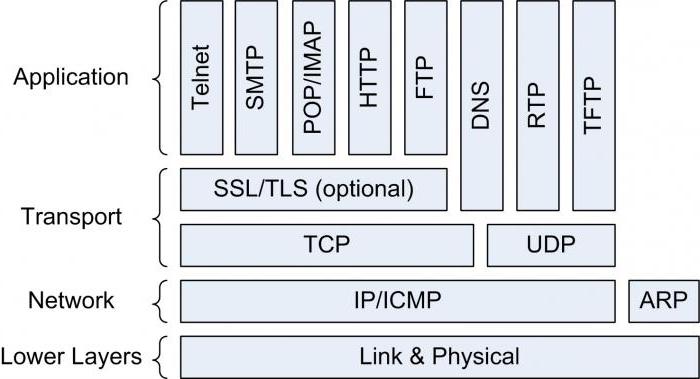
ICMP jest ograniczony ze względu na oryginalne źródło, ale nie z pośrednimi komunikatami ICMP. Są one przesyłane przez Internet w części danych datagramu IP, która sama przechodzi przez sieć. Dlatego są ściśle powiązane z protokołem ARP. Komunikaty ICMP są routowane w taki sam sposób, jak datagramy zawierające informacje dla użytkowników bez dodatkowej niezawodności lub priorytetu.
Występuje wyjątek w procedurach obsługi błędów, gdy datagram IP przenoszący komunikaty ICMP nie jest generowany dla błędów pochodzących z datagramów zawierających komunikaty o błędach.
Format wiadomości ICMP
Ma trzy pola:
- 8-bitowe pole typu całkowitego TYPE identyfikujące komunikat;
- 8-bitowe pole CODE, które dostarcza dodatkowych informacji o jego typie;
- 16-bitowe pole CHECKSUM (ICMP używa tego samego algorytmu sumy kontrolnej, który obejmuje tylko komunikat tego protokołu).
Ponadto komunikaty o błędach ICMP we wszystkich przypadkach obejmują nagłówek i początkowe 64 bity danych datagramów powodujących problem.
Żądania i odpowiedzi
Protokół TCP / IP udostępnia narzędzia, które pomagają administratorom sieci lub użytkownikom identyfikować problemy z siecią. Jednym z najczęściej używanych narzędzi do debugowania jest wywoływanie wywołań echa ICMP i komunikatów odpowiedzi echa. Host lub brama wysyła wiadomość do określonego miejsca docelowego.
Każdy komputer, który odbiera żądanie echa, tworzy odpowiedź i zwraca ją do pierwotnego nadawcy. Żądanie obejmuje opcjonalny obszar odesłania danych. Odpowiedź zawiera kopię danych wysłanych w żądaniu. Ping i odpowiedź z nim powiązana mogą być wykorzystane do sprawdzenia dostępności osiągalnego celu i odpowiedzi.
Ponieważ zarówno żądanie, jak i odpowiedź są wysyłane w datagramach IP, pomyślne potwierdzenie potwierdza, że system działa poprawnie. Aby to zrobić, muszą być spełnione następujące warunki:
- Oprogramowanie źródłowe IP musi trasować datagram;
- Bramy pośrednie z miejscem docelowym i źródłem muszą działać poprawnie i poprawnie trasować datagram;
- Komputer docelowy musi być uruchomiony i musi działać zarówno oprogramowanie ICMP, jak i adres IP;
- Trasy w bramie w drodze powrotnej muszą być poprawne.
Jak to działa?
Praca protokołów ARP i ICMP jest ściśle powiązana. Ilekroć błąd uniemożliwia skierowanie datagramu lub dostarczenie go do bramy, wysyła wiadomość niedostępną adresata z powrotem do kodu źródłowego, a następnie usuwa datagram. Nieprawidłowe problemy z siecią zwykle implikują niepowodzenie transferu danych. Ponieważ wiadomość zawiera krótki prefiks datagramu powodującego problem, źródło dokładnie wie, które adresy są niedostępne. Kierunek może nie być dostępny, ponieważ sprzęt jest tymczasowo wyłączony, nadawca zgłosił nieistniejący adres docelowy lub brama nie ma trasy do docelowej sieci.
Mimo że bramki wysyłają wiadomości poza cel do miejsca przeznaczenia, jeśli nie mogą trasować ani dostarczać datagramów, nie wszystkie takie błędy mogą zostać wykryte. Jeśli datagram zawiera parametr trasy źródłowej z niepoprawnymi danymi, może wywołać komunikat o błędzie trasy źródłowej.