Jaka jest moc alfabetu
Alfabet w informatyce jest systemem znaków, za pomocą którego można przesłać komunikat informacyjny. Aby zrozumieć istotę tej definicji, oto kilka dodatkowych faktów teoretycznych:
- Wszelkie wiadomości składają się z alfabetu. Na przykład ten artykuł jest wiadomością. Następnie składa się ze znaków alfabetu rosyjskiego.
- Pod symbolem możemy zrozumieć minimalną znaczącą cząstkę alfabetu. Również niepodzielne cząsteczki nazywane są atomami. Znaki w alfabecie rosyjskim to "a", a następnie "b", "c" i tak dalej.
- Teoretycznie alfabet nie musi być w żaden sposób kodowany. Na przykład w drukowanej książce symbole alfabetu oznaczają same siebie, co oznacza, że nie mają żadnego kodowania.

Ale w praktyce mamy następujące: komputer nie rozumie, jakie są litery. Dlatego, aby przesłać komunikat informacyjny, musi najpierw zostać zakodowany w języku zrozumiałym dla komputera. Aby przejść dalej, konieczne jest wprowadzenie dodatkowych warunków.
Jaka jest moc alfabetu
Przez moc alfabetu rozumiemy całkowitą liczbę znaków w niej. Aby dowiedzieć się, jaka jest moc alfabetu, wystarczy policzyć liczbę znaków w nim. Rozumiemy to. W przypadku alfabetu rosyjskiego moc alfabetu wynosi 33 lub 32 znaki, jeśli nie używa się "e".
Załóżmy, że wszystkie postacie w naszym alfabecie spotykają się z takim samym prawdopodobieństwem. Założenie to można rozumieć w następujący sposób: załóżmy, że mamy torbę z podpisanymi sześcianami. Liczba zawartych w nim kostek jest nieskończona, a każda z nich jest podpisana tylko jednym symbolem. Następnie, przy równomiernym rozmieszczeniu, bez względu na to, ile kostek wydostaniemy się z torby, liczba kostek z różnymi symbolami będzie taka sama, lub będzie zmierzać do tego ze wzrostem liczby kostek, które wyciągamy z torby.
Ocena wagi komunikatów informacyjnych
Prawie sto lat temu amerykański inżynier Ralph Hartley opracował formułę, którą można ocenić ilość informacji w wiadomości. Jego formuła działa na równie prawdopodobne zdarzenia i wygląda tak:
i = log 2 M
Gdzie "i" to liczba niepodzielnych informacji, czyli atomy (bity) w komunikacie, "M" to moc alfabetu. Kontynuujemy. Za pomocą przekształceń matematycznych możemy określić, że moc alfabetu można obliczyć w następujący sposób:
M = 2 i
Ta formuła w ogólnej formie określa połączenie między liczbą równie prawdopodobnych zdarzeń "M" i ilością informacji "i".
Oblicz moc
Najprawdopodobniej już wiesz na szkolnym kursie informatycznym, że w nowoczesnych systemach komputerowych opartych na architekturze von Neumanna używany jest binarny system kodowania informacji. Oba programy i dane są zakodowane w ten sposób.
Aby przedstawić tekst w systemie komputerowym, użyj jednolitego kodu ośmiu bitów. Kod jest uważany za jednolity, ponieważ zawiera stały zestaw elementów - 0 i 1. Wartości w takim kodzie są określone przez określoną kolejność tych elementów. Za pomocą ośmiobitowego kodu możemy kodować wiadomości ważące 256 bitów, ponieważ według wzoru Hartleya: M 8 = 2 8 = 256 bitów informacji.
Ta sytuacja z kodowaniem znaków w kodzie binarnym rozwinęła się historycznie. Ale teoretycznie moglibyśmy użyć innych alfabetów do reprezentowania danych. Na przykład w czteroliterowym alfabecie każda postać ma wagę nie jednego, ale dwóch bitów, w ośmioznakowym alfabecie - 3 bitach i tak dalej. Jest to obliczane za pomocą logarytmu binarnego podanego powyżej ( i = log 2 M ).
Ponieważ w alfabecie o pojemności 256 bitów, osiem cyfr binarnych jest przypisanych do oznaczenia jednego znaku, zdecydowano wprowadzić dodatkową miarę informacji - bajtów. Jeden bajt zawiera jeden znak tablicy kodów ASCII i zawiera osiem bitów.
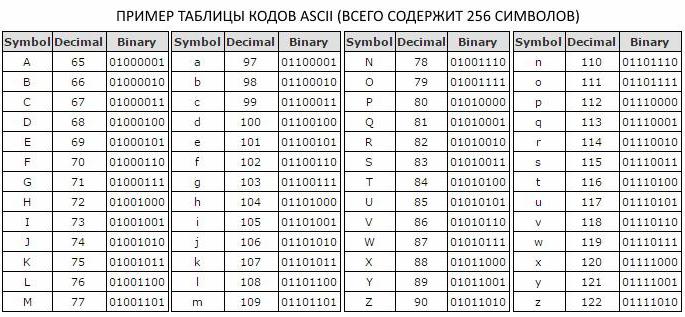
Jak mierzyć informacje
в прописном и строчном варианте, цифры, символы знаков препинания и другие базовые символы. Osiem bitowe kodowanie wiadomości tekstowych, które jest używane w tabeli kodów ASCII, pozwala dopasować podstawowy zestaw znaków alfabetu łacińskiego i cyrylicowego wielkimi i małymi literami, cyframi, znakami interpunkcyjnymi i innymi podstawowymi znakami.
Aby zmierzyć większe ilości danych, użyj specjalnych przedrostków do słów i bitów słów. Takie załączniki przedstawiono w poniższej tabeli:
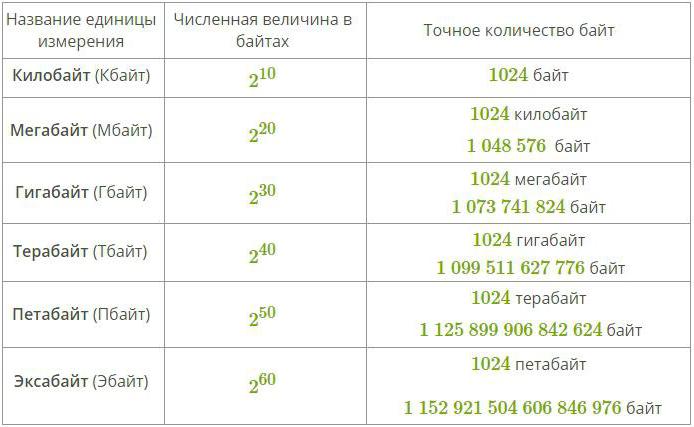
Wiele osób, które studiowały fizykę, będzie argumentować, że racjonalne byłoby używanie klasycznych prefiksów do oznaczania jednostek informacji (takich jak kilo i mega), ale w rzeczywistości nie jest to całkowicie poprawne, ponieważ takie przedrostki do wartości oznaczają mnożenie przez jeden lub inny poziom dziesięciu kiedy binarny system pomiarów jest używany wszędzie w informatyce.
Prawidłowe nazwy jednostek danych
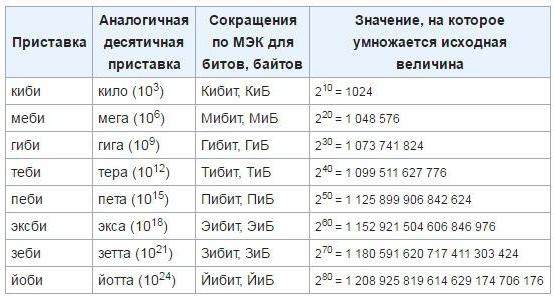
Aby wyeliminować niedokładności i niedogodności, w marcu 1999 r. Międzynarodowa Komisja ds. Elektrotechniki zatwierdziła nowe jednostki dla jednostek, które są wykorzystywane do określenia ilości informacji w elektronicznym systemie komputerowym. Takie przedrostki to "mebi", "kibi", "gibi", "tebi", "eksbi", "petit". Jak dotąd jednostki te jeszcze się nie zakorzeniły, więc najprawdopodobniej potrzeba czasu na wprowadzenie tego standardu i początek powszechnego stosowania. Jak przejść z klasycznych jednostek do nowo zatwierdzonych, możesz określić następującą tabelę:
Załóżmy, że mamy tekst zawierający znaki K. Następnie za pomocą podejścia alfabetycznego można obliczyć ilość informacji V, która zawiera. Będzie równy iloczynowi mocy alfabetu przez wagę informacyjną jednego znaku w niej.
Według formuły Hartleya wiemy, jak obliczyć ilość informacji za pomocą logarytmu binarnego. Zakładając, że liczba znaków alfabetu jest równa N, a liczba znaków w rekordzie wiadomości informacyjnej jest równa K, otrzymujemy następującą formułę do obliczenia objętości informacji w wiadomości:
V = K ⋅ log 2 N
Podejście alfabetyczne wskazuje, że objętość informacji zależy wyłącznie od mocy alfabetu i wielkości wiadomości (to jest liczby znaków w niej), ale w żaden sposób nie będzie związana z treścią semantyczną dla danej osoby.
Przykłady obliczeń mocy
W komputerach klasowych nauka często polega na znalezieniu mocy alfabetu, długości wiadomości lub objętości informacji. Oto jedno z tych zadań:
"Plik tekstowy zajmuje 11 KB miejsca na dysku i zawiera 11264 znaków. Określ moc alfabetu tego pliku tekstowego."
Jakie będzie rozwiązanie, które można zobaczyć na poniższym obrazku.

Tak więc alfabet o pojemności 256 znaków zawiera tylko 8 bitów informacji, które w informatyce nazywa się jeden bajt. Bajt opisuje 1 znak tabeli ASCII, która, jeśli się nad tym zastanowić, wcale nie jest duża.
Czy jeden bajt jest dużo czy mało?
Nowoczesne magazyny danych, takie jak centra danych Google i Facebooka zawierają nie mniej niż dziesiątki petabajtów informacji. Dokładna ilość danych będzie jednak trudna do obliczenia nawet samodzielnie, ponieważ wtedy będziesz musiał zatrzymać wszystkie procesy na serwerach i zamknąć użytkownikom dostęp do nagrywania i edycji ich danych osobowych.

Aby jednak wyobrazić sobie takie niepojęte ilości danych, konieczne jest jasne zrozumienie, że wszystko składa się z drobnych szczegółów. Konieczne jest zrozumienie, jaka jest moc alfabetu (256) i ile bitów zawiera 1 bajt informacji (jak pamiętamy, 8).