Algorytmy genetyczne: istota, opis, przykłady, zastosowanie
Idea algorytmów genetycznych (GA) pojawiła się dość dawno temu (1950-1975), ale stały się prawdziwym przedmiotem badań dopiero w ostatnich dziesięcioleciach. D. Holland był uważany za pioniera w tej dziedzinie, który zapożyczył wiele genetyki i przystosował je do komputerów. GA są szeroko stosowane w systemach sztucznej inteligencji, sieciach neuronowych i problemach optymalizacyjnych.
Wyszukiwanie ewolucyjne
Modele algorytmów genetycznych zostały stworzone w oparciu o ewolucję w dzikich i przypadkowych metodach wyszukiwania. Jednocześnie wyszukiwanie przypadkowe jest implementacją najprostszej funkcji ewolucji - losowych mutacji i późniejszej selekcji.
Z matematycznego punktu widzenia ewolucyjne poszukiwanie to nic innego jak przekształcenie istniejącego skończonego zestawu rozwiązań w nowy. Funkcją odpowiedzialną za ten proces jest wyszukiwanie genetyczne. Główną różnicą takiego algorytmu od losowego wyszukiwania jest aktywne wykorzystanie informacji zgromadzonych podczas iteracji (powtórzeń).
Dlaczego potrzebujemy algorytmów genetycznych
GA ma następujące cele:
- wyjaśnić mechanizmy adaptacji zarówno w środowisku naturalnym, jak iw systemie badań intelektualnych (sztucznych);
- modelowanie funkcji ewolucyjnych i ich zastosowanie do efektywnego poszukiwania rozwiązań różnych problemów, głównie optymalizacyjnych.
Obecnie istotę algorytmów genetycznych i ich zmodyfikowanych wersji można nazwać poszukiwaniem skutecznych rozwiązań, biorąc pod uwagę jakość wyniku. Innymi słowy, znalezienie najlepszej równowagi pomiędzy wydajnością i precyzją. Dzieje się tak ze względu na dobrze znany paradygmat "przetrwania najlepiej dostosowanej osoby" w niepewnych i niewyraźnych warunkach.
Funkcje GA
Podajemy główne różnice w GA od większości innych metod znajdowania optymalnego rozwiązania.
- pracować z parametrami zadania, kodować w określony sposób, a nie bezpośrednio z nimi;
- poszukiwanie rozwiązania nie następuje poprzez określenie początkowego przybliżenia, ale w zestawie możliwych rozwiązań;
- wykorzystując tylko funkcję celu, bez uciekania się do jej pochodnych i modyfikacji;
- zastosowanie probabilistycznego podejścia do analizy, zamiast podejścia ściśle deterministycznego.
Kryteria wydajności
Algorytmy genetyczne wykonują obliczenia na podstawie dwóch warunków:
- Wykonaj określoną liczbę iteracji.
- Jakość znalezionego rozwiązania spełnia wymagania.
Jeśli jeden z tych warunków zostanie spełniony, algorytm genetyczny przestanie wykonywać kolejne iteracje. Ponadto użycie GA w różnych regionach przestrzeni rozwiązania pozwala im znaleźć znacznie lepsze nowe rozwiązania, które mają bardziej odpowiednie wartości funkcji celu.
Podstawowa terminologia
Z uwagi na fakt, że GA opiera się na genetyki, odpowiada ona większości terminologii. Każdy algorytm genetyczny działa na podstawie początkowej informacji. Zbiorem wartości początkowych jest populacja t t = {n 1 , n 2 , ..., n n }, gdzie n i = {r 1 , ..., r v }. Zbadamy bardziej szczegółowo:
- t to numer iteracji. t 1 , ..., t k - oznacza iterację algorytmu z liczby 1 do k, a przy każdej iteracji tworzona jest nowa populacja rozwiązań.
- n jest wielkością populacji P t .
- 1 , ..., п i - хромосома, особь, или организм. n 1 , ..., n i - chromosom, osobnik lub organizm. Chromosom lub łańcuch to zakodowana sekwencja genów, z których każda ma numer sekwencji. Należy pamiętać, że chromosom może być szczególnym przypadkiem jednostki (organizmu).
- rv są genami, które są częścią zakodowanego rozwiązania.
- Locus to numer sekwencji genu w chromosomie. Allele to wartość genowa, która może być zarówno numeryczna, jak i funkcjonalna.
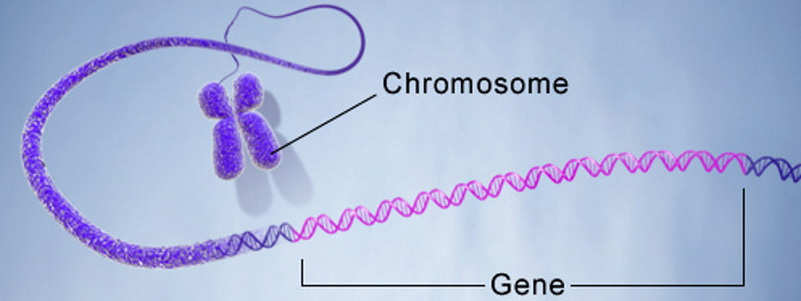
Co oznacza "zakodowany" w kontekście GA? Zwykle każda wartość jest kodowana na podstawie alfabetu. Najprostszym przykładem jest konwersja liczb z dziesiętnego systemu liczbowego na binarną. Zatem alfabet jest reprezentowany jako zbiór {0, 1}, a liczba 157 10 będzie kodowana przez chromosom 10011101 2 , składający się z ośmiu genów.
Rodzice i potomkowie
Rodzice to elementy wybrane zgodnie z danym warunkiem. Na przykład często ten warunek jest przypadkiem. Wybrane elementy ze względu na operacje krzyżowania i mutacji dają początek nowym, zwanym potomstwem. Tak więc rodzice podczas wdrażania jednej iteracji algorytmu genetycznego tworzą nową generację.
Wreszcie, ewolucja w tym kontekście będzie przemianą pokoleń, z których każdy nowy będzie się wyróżniał zestawem chromosomów dla lepszej kondycji, czyli bardziej odpowiednią zgodnością z określonymi warunkami. Ogólne tło genetyczne w procesie ewolucji nazywa się genotypem, a tworzenie się połączenia organizmu ze środowiskiem zewnętrznym nazywa się fenotypem.
Funkcja fitness
Magia algorytmu genetycznego w funkcji fitness. Każda osoba ma swoją własną wartość, którą można nauczyć się dzięki funkcji adaptacji. Jego głównym zadaniem jest ocena tych wartości dla różnych alternatywnych rozwiązań i wybór najlepszego. Innymi słowy, najsilniejszy.
W problemach optymalizacji funkcja fitness nazywana jest celem, w teorii sterowania nazywana jest błędem, w teorii gier jest funkcją wartości i tak dalej. To, co dokładnie zostanie przedstawione jako funkcja adaptacji, zależy od problemu, który należy rozwiązać.
Ostatecznie można stwierdzić, że algorytmy genetyczne analizują populację osobników, organizmów lub chromosomów, z których każdy jest reprezentowany przez kombinację genów (zestaw niektórych wartości) i poszukiwanie optymalnego rozwiązania, transformując jednostki populacji poprzez sztuczną ewolucję między nimi.
Odchylenia w jednym lub drugim kierunku poszczególnych elementów w ogólnym przypadku są zgodne z normalnym prawem dystrybucji ilości. W tym samym czasie GA zapewnia dziedziczność cech, z których najbardziej przystosowane są ustalone, zapewniając tym samym najlepszą populację.
Podstawowy algorytm genetyczny
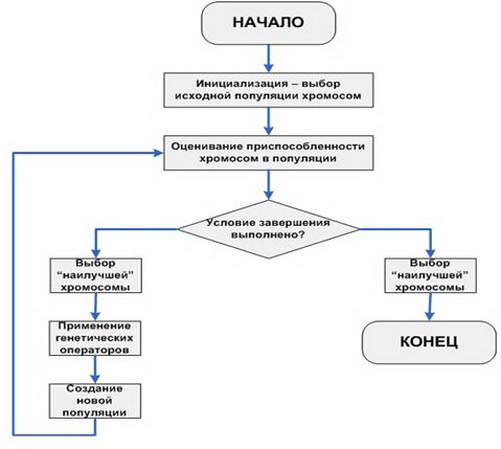
Rozkładamy w krokach najprostsze (klasyczne) GA.
- Inicjalizacja wartości początkowych, czyli definicja populacji pierwotnej, zbioru osób, z którymi nastąpi ewolucja.
- Ustalenie podstawowej sprawności każdej osoby w populacji.
- Sprawdź warunki zakończenia dla iteracji algorytmu.
- Korzystanie z funkcji wyboru.
- Wykorzystanie operatorów genetycznych.
- Tworzenie nowej populacji.
- Etapy 2-6 powtarza się w cyklu aż do spełnienia wymaganego warunku, po czym następuje wybór najbardziej dostosowanego osobnika.
Przejdźmy przez krótką chwilę przez mało oczywiste części algorytmu. Istnieją dwa warunki rozwiązania:
- Liczba iteracji.
- Jakość rozwiązania.
Operatory genetyczne są operatorem mutacji i operatorem crossover. Mutacja zmienia losowe geny z pewnym prawdopodobieństwem. Z reguły prawdopodobieństwo mutacji ma niską wartość liczbową. Porozmawiajmy więcej o procedurze algorytmu genetycznego "przekraczanie". Występuje zgodnie z następującą zasadą:
- Dla każdej pary rodziców zawierającej geny L, punkt przecięcia Tsk i jest wybierany losowo.
- Pierwszy potomek składa się z połączenia [1; Tsk i ] geny pierwszego rodzica [Tsk i + 1 ; L] geny drugiego rodzica.
- Drugi potomek składa się w odwrotny sposób. Teraz do genów drugiego rodzica [1; Tsk i ] dodaje geny pierwszego rodzica w pozycjach [Tsk i + 1 ; L].
Trivial przykład
Rozwiązujemy problem za pomocą algorytmu genetycznego na przykładzie wyszukiwania osoby o maksymalnej liczbie jednostek. Niech dana osoba składa się z 10 genów. Przydzielamy populację pierwotną w liczbie ośmiu osobników. Oczywiście najlepszą osobą powinno być 1111111111. Uzupełnijmy decyzję GA.
- Inicjalizacja. Wybierz 8 losowych osób:
| n 1 | 1110010101 | n 5 | 0101000110 |
| n 2 | 1100111010 | n 6 | 0100110101 |
| n 3 | 1110011110 | n 7 | 0110111011 |
| n 4 | 1011000000 | n 8 | 0100001001 |
- Ocena kondycji. Oczywiście, w naszym algorytmie genetycznym funkcja fitness F będzie liczyć liczbę jednostek w każdej osobie. Tak więc mamy:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 6 | 7 | 8 | 3 | 4 | 5 | 7 | 3 |
Tabela pokazuje, że osoby 3 i 7 mają największą liczbę jednostek, a zatem są najbardziej odpowiednimi członkami populacji, aby rozwiązać problem. Ponieważ w tej chwili nie ma rozwiązania wymaganej jakości, algorytm nadal działa. Konieczne jest przeprowadzenie selekcji osób. Aby ułatwić wyjaśnienie, niech wybór będzie losowy, a otrzymamy próbkę osobników {n 7 , n 3 , n 1 , n 7 , n 3 , n 7 , n 4 , n 2 } - są to rodzice nowej populacji.
- Wykorzystanie operatorów genetycznych. Ponownie, dla uproszczenia, zakładamy, że prawdopodobieństwo mutacji wynosi 0. Innymi słowy, wszystkie 8 osób przekazuje swoje geny takimi, jakie są. Aby przejść, losowo parujemy pary: (n 2 , n 7 ), (n 1 , n 7 ), (n 3 , n 4 ) i (n 3 , n 7 ). W ten sam losowy sposób wybiera się punkty przejścia dla każdej pary:
| Para | (p 2 , s 7 ) | (n 1 , n 7 ) | (p 3 , p 4 ) | (p 3 , p 7 ) |
| Rodzice | [1100111010] [0110111011] | [1110010101] [0110111011] | [1110011110] [1011000000] | [1110011110] [0110111011] |
| Tsk i | 3 | 5 | 2 | 8 |
| Potomkowie | [1100111011] [0110111010] | [1110011011] [0110110101] | [1111000000] [1010011110] | [1110011111] [0110111010] |
- Kompilacja nowej populacji składającej się z potomków:
| n 1 | 1100111011 | n 5 | 1111000000 |
| n 2 | 0110111010 | n 6 | 1010011110 |
| n 3 | 1110011011 | n 7 | 1110011111 |
| n 4 | 0110110101 | n 8 | 0110111010 |
- Oceniamy kondycję każdej osoby z nowej populacji:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 7 | 6 | 7 | 6 | 4 | 6 | 8 | 6 |
Dalsze działania są oczywiste. Najbardziej interesującą rzeczą w GA jest, jeśli oszacujemy średnią liczbę jednostek w każdej populacji. W pierwszej populacji średnio było 5.375 jednostek dla każdej osoby, w populacji potomków - 6.25 jednostek na osobę. I taka cecha będzie obserwowana nawet wtedy, gdy podczas mutacji i przekraczania jednostka traci największą liczbę jednostek w pierwszej populacji.
Plan wdrożenia
Tworzenie algorytmu genetycznego jest dość skomplikowanym zadaniem. Najpierw wymieniamy plan w postaci kroków, po czym przeanalizujemy każdą z nich bardziej szczegółowo.
- Definicja reprezentacji (alfabet).
- Definicja operatorów zmian losowych.
- Definicja przetrwania jednostek.
- Generowanie populacji pierwotnej.
Pierwszy etap mówi, że alfabet, w którym wszystkie elementy zestawu rozwiązań lub populacji zostaną zakodowane, musi być wystarczająco elastyczny, aby umożliwić przeprowadzenie niezbędnych permutacji losowych w tym samym czasie i ocenić kondycję elementów, zarówno podstawowych, jak i tych, które przeszły przez zmiany. Matematycznie ustalono, że niemożliwe jest stworzenie idealnego alfabetu do tych celów, dlatego jego kompilacja jest jednym z najtrudniejszych i najważniejszych kroków w celu zapewnienia stabilnego działania GA.

Równie trudno jest zdefiniować zmiany i stworzyć potomków. Istnieje wielu operatorów, którzy są w stanie wykonać wymagane działania. Na przykład z biologii wiadomo, że każdy gatunek może się rozmnażać na dwa sposoby: seksualnie (przez krzyżowanie) i bezpłciowy (przez mutacje). W pierwszym przypadku rodzice wymieniają materiał genetyczny, w drugim - występują mutacje, określone przez wewnętrzne mechanizmy ciała i wpływ zewnętrzny. Ponadto można stosować modele reprodukcyjne, których nie ma w dzikiej zwierzynie. Na przykład użyj genów trzech lub więcej rodziców. Podobnie, krzyżowanie mutacji w algorytmie genetycznym może obejmować różnorodny mechanizm.
Wybór metody przeżycia może być niezwykle zwodniczy. Algorytm genetyczny do hodowli ma wiele sposobów. I, jak pokazuje praktyka, zasada "przetrwania najsilniejszych" nie zawsze jest najlepsza. Przy rozwiązywaniu złożonych problemów technicznych często okazuje się, że najlepsze rozwiązanie pochodzi z wielu średnich lub nawet gorszych. Dlatego często przyjmuje się podejście probabilistyczne, które stwierdza, że najlepsze rozwiązanie ma większą szansę na przeżycie.

Ostatni etap zapewnia elastyczność algorytmu, którego nie ma nikt inny. Początkową populację roztworów można określić na podstawie dowolnych znanych danych lub w całkowicie losowy sposób, po prostu przestawiając geny wewnątrz osobników i tworząc przypadkowe osoby. Jednak zawsze warto pamiętać, że skuteczność algorytmu zależy od początkowej populacji.
Skuteczność
Skuteczność algorytmu genetycznego zależy wyłącznie od poprawności kroków opisanych w planie. Szczególnie ważnym elementem jest tutaj tworzenie populacji pierwotnej. Istnieje wiele podejść do tego. Opiszemy kilka:
- Stworzenie kompletnej populacji, która obejmie wszystkie rodzaje opcji dla osób w danym obszarze.
- Losowe tworzenie osób na podstawie wszystkich prawidłowych wartości.
- Dowolne losowe tworzenie jednostek, gdy wśród dopuszczalnych wartości wybierany jest zakres generowania.
- Łącząc pierwsze trzy sposoby tworzenia populacji.

Możemy więc stwierdzić, że skuteczność algorytmów genetycznych zależy w dużym stopniu od doświadczenia programisty w tej kwestii. Jest to zarówno wadą algorytmów genetycznych, jak i ich zaletą.