Kod genetyczny: opis, cechy, historia badań
Każdy żywy organizm ma specjalny zestaw białek. Niektóre związki nukleotydowe i ich sekwencja w Cząsteczka DNA tworzą kod genetyczny. Przekazuje informacje o strukturze białka. W genetyce przyjęto pewną koncepcję. Według niej jeden enzym (polipeptyd) odpowiadał jednemu genowi. Należy stwierdzić, że badania nad kwasami nukleinowymi i białkami prowadzone były przez dość długi czas. W dalszej części artykułu przyjrzymy się bliżej kodzie genetycznemu i jego właściwościom. Zostanie również podana krótka chronologia badań. 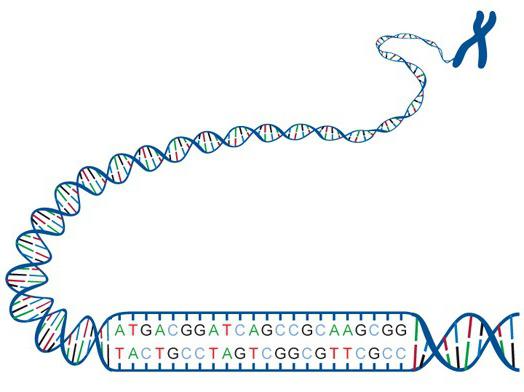
Terminologia
Kod genetyczny jest metodą kodowania sekwencji białek aminokwasowych obejmujących sekwencję nukleotydową. Ta metoda tworzenia informacji jest charakterystyczna dla wszystkich żywych organizmów. Białka są naturalnie występującymi substancjami organicznymi o wysokiej masie cząsteczkowej. Związki te są również obecne w żywych organizmach. Składają się z 20 rodzajów aminokwasów, które nazywane są kanonicznymi. Aminokwasy są ułożone w łańcuch i połączone w ściśle określonej kolejności. Określa struktura białka i jego właściwości biologiczne. Istnieje również kilka łańcuchów aminokwasów w białku. 
DNA i RNA
Kwas dezoksyrybonukleinowy jest makrocząsteczką. Odpowiada za przesyłanie, przechowywanie i wdrażanie informacji dziedzicznych. DNA wykorzystuje cztery zasady azotowe. Należą do nich adenina, guanina, cytozyna, tymina. RNA składa się z tych samych nukleotydów, oprócz tego, które zawierają tyminę. Zamiast tego jest nukleotyd zawierający uracyl (U). Cząsteczki RNA i DNA to łańcuchy nukleotydów. Ze względu na tę strukturę tworzą się sekwencje - "alfabet genetyczny".
Wdrażanie informacji
Synteza białek, który jest kodowany przez gen, jest realizowany przez połączenie mRNA na matrycy DNA (transkrypcja). Również przeniesienie kodu genetycznego w sekwencji aminokwasów. Oznacza to, że istnieje synteza łańcucha polipeptydowego na mRNA. Aby zaszyfrować wszystkie aminokwasy i sygnalizować koniec sekwencji białka wystarczy 3 nukleotydy. Ten łańcuch nazywa się trypletem. 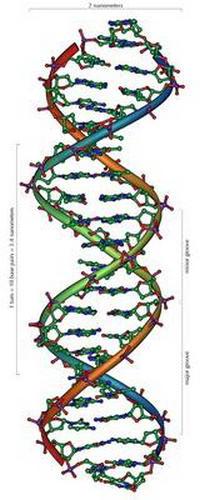
Historia badań
Badanie białka i kwasy nukleinowe trzymany przez długi czas. W połowie XX wieku pojawiły się pierwsze pomysły dotyczące natury kodu genetycznego. W 1953 stwierdzono, że niektóre białka składają się z sekwencji aminokwasów. To prawda, że nie byli jeszcze w stanie określić ich dokładnej liczby i było wiele sporów w tej sprawie. W 1953 roku opublikowano dwie prace autorstwa Watsona i Cricka. Pierwszy zadeklarował wtórną strukturę DNA, drugi mówił o jego dopuszczalnym kopiowaniu za pomocą syntezy macierzy. Ponadto położono nacisk na fakt, że określona sekwencja zasad jest kodem, który przenosi dziedziczną informację. Amerykański i radziecki fizyk Georgy Gamov pozwolił sobie na hipotezę kodowania i znalazł metodę jej weryfikacji. W 1954 r. Opublikowano jego pracę, w trakcie której przedstawił propozycję ustalenia odpowiedników między bocznymi łańcuchami aminokwasów a "dziurami", które mają romboidalny kształt i wykorzystują to jako mechanizm kodujący. Następnie został nazwany rombem. Wyjaśniając swoją pracę, Gamow przyznał, że kod genetyczny może być trypletem. Fizyka pracy była jedną z pierwszych osób, które uznano za bliskie prawdy. 
Klasyfikacja
Po kilku latach zaproponowano różne modele kodów genetycznych, reprezentujące dwa typy: nakładające się i nie pokrywające się. Podstawą pierwszego było wejście jednego nukleotydu w kilka kodonów. Do tego należy trójkątny, sekwencyjny i znaczny mniejszy kod genetyczny. Drugi model obejmuje dwa typy. Brak nakładania się są kombinacyjne i "kod bez przecinków". Pierwszy wariant opiera się na kodowaniu aminokwasowym trypletów nukleotydowych, a najważniejszą jest jego skład. Według "kodu bez przecinków", niektóre trojaczki odpowiadają aminokwasom, a reszta nie. W tym przypadku uważano, że jeśli jakiekolwiek znaczące triplety zostały ułożone sekwencyjnie, inne, które byłyby w innej ramce odczytu, byłyby niepotrzebne. Naukowcy byli przekonani, że istnieje możliwość wyboru sekwencji nukleotydów, która spełni te wymagania, oraz że istnieje dokładnie 20 trojaczków.  Chociaż Gamow i wsp. Kwestionowali taki model, uznano go za najbardziej poprawny na następne pięć lat. Na początku drugiej połowy XX wieku pojawiły się nowe dane, które ujawniły pewne błędy w "bezkodowym kodzie". Stwierdzono, że kodony mogą wywoływać syntezę białek in vitro. W 1965 r. Została opanowana zasada wszystkich 64 trojaczków. W rezultacie odkrył nadmiar niektórych kodonów. Innymi słowy, sekwencja aminokwasowa jest kodowana przez kilka tripletów.
Chociaż Gamow i wsp. Kwestionowali taki model, uznano go za najbardziej poprawny na następne pięć lat. Na początku drugiej połowy XX wieku pojawiły się nowe dane, które ujawniły pewne błędy w "bezkodowym kodzie". Stwierdzono, że kodony mogą wywoływać syntezę białek in vitro. W 1965 r. Została opanowana zasada wszystkich 64 trojaczków. W rezultacie odkrył nadmiar niektórych kodonów. Innymi słowy, sekwencja aminokwasowa jest kodowana przez kilka tripletów.
Cechy wyróżniające
Właściwości kodu genetycznego obejmują:
- Triplet. Sekwencja trzech nukleotydów jest znaczącą jednostką kodu.
- Ciągłość. Trojaczki nie mają znaki interpunkcyjne istnieje ciągła lektura informacji.
- Pokrywanie się. Nukleotyd jest częścią tylko jednego trypletu. W niektórych genach wirusów, bakterii i mitochondriów szereg białek jest kodowanych i pojawia się odczyt przesunięcia ramki.
- Jednoznaczność. Specyficzny kodon odpowiada nie więcej niż jednemu aminokwasowi. To prawda, że Euplotescrassus UGA może kodować cysteinę i silenocysteinę.
- Degeneracja Specyficzny aminokwas odpowiada kilku kodonom.
- Wszechstronność. Kod genetyczny działa na tej samej zasadzie w organizmach o różnej złożoności. To jest esencja inżynierii genetycznej. Istnieją jednak wyjątki.
- Odporność na zakłócenia. Mutacyjne podstawienia nukleotydów są konserwatywne i radykalne. Pierwszy nie prowadzi do zmiany w klasie kodowanego aminokwasu. Radykalne mutacje zmieniają klasę kodowanego aminokwasu.
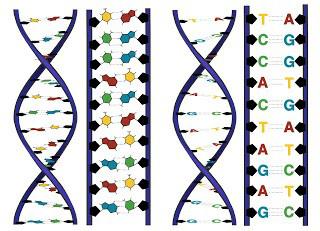
Wariacje
Po raz pierwszy odchylenie kodu genetycznego od standardowego zostało odkryte w 1979 roku podczas badania genów mitochondrialnych w ludzkim ciele. Ponadto zidentyfikowano bardziej podobne warianty, w tym wiele alternatywnych kodów mitochondrialnych. Obejmują one dekodowanie kodonu stop CAA, który jest stosowany jako definicja tryptofanu w mykoplazmach. GUG i CCG w archeach i bakteriach są często stosowane jako warianty startowe. Czasami geny kodują białko z kodonu startowego, który różni się od standardu stosowanego przez ten gatunek. Ponadto w niektórych białkach selenocysteina i pirolysyna, które są niestandardowymi aminokwasami, są wstawiane przez rybosom. Czyta kodon stop. To zależy od sekwencji znalezionych w mRNA. Obecnie selenocysteina jest uważana za 21., pirolizan - 22. aminokwas występujący w składzie białek.
Wspólne cechy kodu genetycznego
Jednak wszystkie wyjątki są rzadkie. W żywych organizmach, głównie kod genetyczny ma wiele wspólnych cech. Obejmują one skład kodonu, który obejmuje trzy nukleotydy (pierwsze dwa należą do decydujących), transfer kodonów tRNA i rybosomów w sekwencji aminokwasowej.