Przestrzenna dyskretyzacja. Przetwarzanie grafiki
W tamtych czasach, kiedy komputery nadal nie miały tak potężnych możliwości jak teraz, nie było mowy o przekształcaniu obrazów na papierze lub na filmie. Obecnie uważa się, że takie obiekty odpowiadają formie analogowej. Wraz z pojawieniem się nowych technologii stało się możliwe cyfryzowanie (na przykład za pomocą skanerów). Z tego powodu pojawiła się tak zwana dyskretna forma obrazów. Ale w jaki sposób przeniesienie grafiki z jednej formy do drugiej? Krótko o istocie takich metod dalej i powiedzą jak najdokładniej i po prostu tak, aby każdy użytkownik zrozumiał, co jest powiedziane.
Czym jest dyskretyzacja przestrzenna w informatyce?
Na początek rozważ ogólną koncepcję, wyjaśniając ją w najprostszym języku. Z jednej formy na drugą obraz graficzny jest przekształcany poprzez przestrzenną dyskretyzację. Aby zrozumieć, co to jest, rozważ prosty przykład.
Jeśli zrobisz zdjęcie namalowane akwarelami, łatwo zauważyć, że wszystkie przejścia są płynne (ciągłe). Ale na zeskanowanym obrazie, który został wydrukowany na drukarce atramentowej, nie ma takich przejść, ponieważ składa się z wielu małych kropek, zwanych pikselami. Okazuje się, że piksel jest rodzajem bloku konstrukcyjnego, który ma określone właściwości (na przykład ma własny kolor lub odcień). Z takich klocków rozwija się pełny obraz.
Jaka jest esencja metody dyskretyzacji przestrzennej?
Jeśli mówimy o istocie metody przekształcania grafiki za pomocą takich technologii, możemy podać inny przykład, który pomoże ci zrozumieć, jak to wszystko działa.
Cyfrowe obrazy, które po zeskanowaniu, które wyświetlają się na ekranie monitora komputera, mogą zostać porównane z mozaiką. Tylko tutaj piksel pojawia się jako jeden element mozaiki. Jest to jedna z głównych cech wszystkich nowoczesnych urządzeń. Jak można było się domyślić, im więcej takich punktów, a im mniejszy rozmiar każdego z nich, tym bardziej płynne będą przejścia. Ostatecznie to ich liczba dla każdego urządzenia determinuje jego rozdzielczość. W informatyce często taką charakterystyką jest zliczanie liczby pikseli (punktów) na cal (dpi - punkt na cal), zarówno w kierunku pionowym, jak i poziomym.
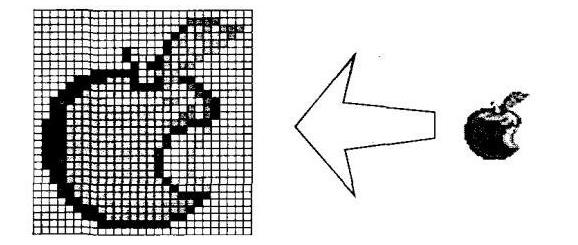
W ten sposób powstaje dwuwymiarowa siatka przestrzenna, nieco przypominająca konwencjonalny układ współrzędnych. Dla każdego punktu w takim systemie można ustawić własne parametry, które będą różne od sąsiednich punktów.
Czynniki wpływające na jakość kodowania
Ale nie tylko powyższe przykłady w pełni odzwierciedlają sposób, w jaki działa dyskretna dyskrecja. Kodowanie informacji graficznej uwzględnia kilka ważniejszych parametrów, które wpływają na jakość zdigitalizowanego obrazu. Dotyczą one nie tylko samych obrazów, ale także urządzeń odtwarzających grafikę.
Przede wszystkim obejmuje to następujące cechy:
- częstotliwość próbkowania;
- rozdzielczość;
- głębia koloru
Częstotliwość próbkowania
Częstotliwość próbkowania jest wielkością fragmentów tworzących obraz. Ten parametr można znaleźć równie dobrze w charakterystyce zdigitalizowanych obrazów, skanerów, drukarek, monitorów i kart graficznych.
To prawda, że jest jeden szkopuł. Faktem jest, że zwiększając całkowitą liczbę punktów można uzyskać wyższą częstotliwość. Jednocześnie rozmiar pliku zapisanego oryginału zmienia się odpowiednio. Aby tego uniknąć, obecnie stosuje się sztuczne utrzymywanie wielkości na jednym stałym poziomie.
Pojęcie rozdzielczości
Ten parametr został już wspomniany. Jeśli jednak spojrzysz na urządzenia wyświetlające obraz, obraz jest nieco inny.

Jako przykład parametrów wykorzystywanych w dyskretnej przestrzeni, rozważ skanery. Na przykład w charakterystyce urządzenia o określonej rozdzielczości 1200 x 1400 dpi. Skanowanie odbywa się poprzez przesunięcie paska światłoczułych elementów wzdłuż skanowanego obrazu. Ale pierwsza cyfra wskazuje rozdzielczość optyczną samego urządzenia (liczba elementów skanujących w jednym calu paska), a druga odnosi się do rozdzielczości sprzętowej i określa liczbę "mikro-ruchów" paska z elementami skanującymi na obrazie, gdy jeden cal przejdzie.
Głębokość koloru
Przed nami kolejny ważny parametr, bez względu na który w pełni rozumiemy, czym jest przestrzenna dyskretyzacja. Głębia koloru (lub głębia kodowania) jest zwykle wyrażana w bitach (to samo, nawiasem mówiąc, można przypisać głębi dźwięku) i określa liczbę kolorów, które były zaangażowane w konstrukcję obrazu, ale ostatecznie odnosi się do palet (zestawów kolorów).

Na przykład, jeśli weźmiemy pod uwagę czarno-białą paletę, która zawiera tylko dwa kolory (bez gradacji odcieni szarości), ilość informacji podczas kodowania każdego punktu można go obliczyć za pomocą powyższego wzoru, biorąc pod uwagę, że N jest całkowitą liczbą kolorów (w naszym przypadku N = 2), a I jest liczbą stanów, które może przyjąć każdy punkt (w naszym przypadku I = 1, ponieważ tylko dwie: czarne lub białe). Zatem N I = 2 1 = 1 bit.
Kwantyzacja
Przestrzenna dyskretyzacja może również uwzględniać parametr zwany kwantyzacją. Co to jest? Pod pewnymi względami przypomina technikę interpolacji.
Istotą procesu jest to, że wartość odniesienia sygnału jest zastępowana przez najbliższą sąsiadującą wartość ze stałego zestawu, który jest listą poziomów kwantyzacji.
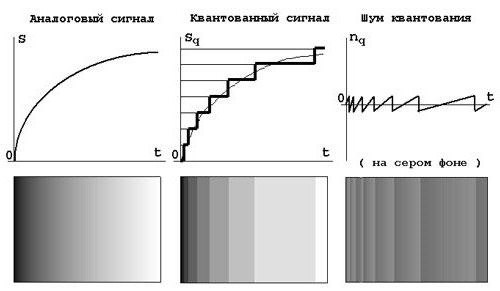
Aby lepiej zrozumieć, w jaki sposób konwertowane są informacje graficzne, spójrz na powyższy obrazek. Przedstawia grafikę w oryginale (postać analogowa), obraz z zastosowaniem kwantyzacji i zniekształceń bocznych, zwany szumem. Na drugim zdjęciu z góry widać osobliwe przejścia. Nazywane są skalami kwantyzacji. Jeśli wszystkie przejścia są takie same, skala nazywa się jednolitą.
Kodowanie cyfrowe
Podczas konwersji informacji graficznej należy zauważyć, że w przeciwieństwie do sygnału analogowego sygnał kwantowy może przyjmować tylko bardzo określoną stałą liczbę wartości. Pozwala to na ich konwersję w zestaw znaków i znaków, których kolejność nazywa się kodem. Ostateczna sekwencja jest nazywana słowem kodowym.
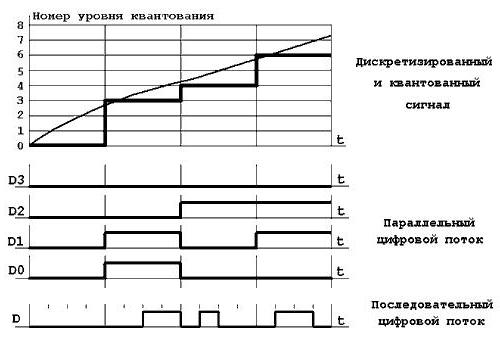
Każde słowo kodowe odpowiada jednemu okresowi kwantyzacji, a kod binarny jest używany do kodowania. Czasami jednak powinieneś wziąć pod uwagę szybkość transmisji danych, która jest iloczynem częstotliwości próbkowania i długości słowa kodowego i jest wyrażana w bitach na sekundę (bps). Z grubsza rzecz biorąc, jest to nic więcej niż maksymalna możliwa liczba transmitowanych symboli binarnych na jednostkę czasu.
Przykład obliczania pamięci wideo do wyświetlania obrazu rastrowego na monitorze
Wreszcie kolejny ważny aspekt związany z tym, co stanowi przestrzenną dyskretyzację. Obrazy rastrowe na ekranie monitora są odtwarzane zgodnie z określonymi regułami i wymagają pamięci.
Na przykład monitor jest ustawiony na tryb graficzny o rozdzielczości 800 x 600 punktów na cal i głębokości kolorów 24-bitowych. Całkowita liczba punktów będzie wynosić 800 x 600 x 24 bity = 11 520 000 bitów, co odpowiada 1 440 000 bajtom, czyli 1406.25 Kb lub 1,37 MB.
Metody kompresji wideo
Technologia przestrzennej dyskretyzacji, jak już jest jasne, ma zastosowanie nie tylko do grafiki, ale także do obrazów wideo, które w pewnym sensie można również przypisać do informacji graficznej (wizualnej). To prawda, że taki materiał został zdigitalizowany przez pewien czas z ograniczonymi możliwościami, ponieważ ostateczne pliki były tak duże, że przechowywanie ich na twardym dysku komputera było niepraktyczne (należy pamiętać przynajmniej o oryginalnym formacie AVI opracowanym przez Microsoft w tym samym czasie).
Wraz z pojawieniem się algorytmów M-JPEG, MPEG-4 i H.64 stało się możliwe zredukowanie ostatecznych plików przy współczynniku redukcji 10-400 razy. Wielu może twierdzić, że skompresowane wideo będzie niższej jakości niż oryginał. W pewnym sensie tak jest. Jednak w takich technologiach zmniejszenie rozmiaru można uzyskać z utratą jakości i bez strat.
Istnieją dwie główne metody wykonywania kompresji: intraframe i interframe. Obie te opcje są oparte na wykluczeniu zduplikowanych elementów z obrazu, ale nie wpływają na przykład na zmiany jasności, koloru itp. Co jest w pierwszym, że w drugim przypadku różnica między scenami w jednej ramce lub między dwoma sąsiednimi jest nieznaczna, a więc różnica w oku nie jest szczególnie zauważalna. Jednak podczas usuwania powyższych elementów z pliku różnica w wielkości oryginalnego i ostatecznego obrazu jest bardzo znacząca.
Jedną z najciekawszych, choć dość złożonych metod, które wykorzystuje przestrzenna dyskretyzacja do kompresji obrazów, jest technologia zwana dyskretną transformacją kosinusową, zaproponowana przez V. Chena w 1981 roku. Opiera się na macierzy, w której, w przeciwieństwie do pierwotnej, która opisuje tylko wartości próbek, przedstawiono wartości szybkości ich zmiany.
W związku z tym można go uznać za pewną siatkę zmian prędkości w kierunku pionowym i poziomym. Rozmiar każdego bloku jest określany przez technologię JPEG i wynosi 8 x 8 pikseli. Kompresja jest stosowana do każdego pojedynczego bloku, ale nie do całego obrazu. W związku z tym różnica pomiędzy materiałem źródłowym a końcowym staje się jeszcze mniej zauważalna. Czasami w terminologii komputerowej taka technika nazywana jest również podpróbkowaniem.
Ponadto, luminancja i chromatyczność mogą być zastosowane do kwantyzacji opisanej powyżej, w której każda wartość transformacji kosinusowej jest dzielona przez współczynnik kwantyzacji, który można znaleźć w specjalnych tabelach opartych na tak zwanych testach psychofizycznych.
Same tabele odpowiadają ściśle zdefiniowanym klasom bloków pogrupowanych według aktywności (jednolity obraz, niestrukturalny obraz, różnica pozioma lub pionowa itp.). Innymi słowy, dla każdego bloku ustawiane są jego własne wartości, które nie mają zastosowania do sąsiadów lub tych, które różnią się klasą.
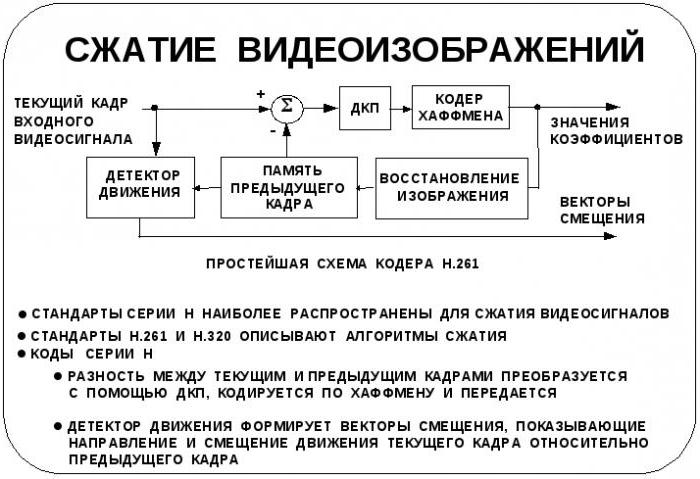
Na koniec, po kwantyzacji, na podstawie kodu Huffmana, wykonywane jest usuwanie nadmiarowych współczynników (redukcja redundancji), co umożliwia uzyskanie słowa kodowego o długości mniejszej niż jeden bit dla każdego współczynnika (VLC) dla późniejszego kodowania. Następnie tworzona jest sekwencja liniowa, dla której stosowana jest metoda odczytu zygzakowego, która grupuje wartości w ostatecznej macierzy w postaci znaczących wartości i ciągów zer. Ale tak jak można je usunąć. Pozostałe kombinacje są kompresowane w standardowy sposób.
Ogólnie rzecz biorąc, eksperci nie zalecają szczególnie kodowania informacji graficznych przy użyciu technologii JPEG, ponieważ mają one kilka wad. Po pierwsze, wielokrotne przywracanie plików niezmiennie prowadzi do pogorszenia jakości. Po drugie, ze względu na to, że obiekty zakodowane w formacie JPEG nie mogą zawierać obszarów przezroczystych, możliwe jest zastosowanie takich metod do obrazów graficznych lub zeskanowanych próbek grafiki artystycznej tylko wtedy, gdy w pionie i w poziomie nie przekraczają one rozmiaru w 200 pikseli. W przeciwnym razie pogorszenie jakości końcowego obrazu zostanie wyrażone bardzo jasno.
To prawda, że algorytmy JPEG stały się podstawą dla technologii kompresji MPEG, a także dla różnych standardów konferencyjnych, takich jak H.26X i H32X.
Zamiast posłowia
Oto krótki i wszystko, co dotyczy zrozumienia zagadnień związanych z przekształceniem analogowej formy grafiki i wideo w dyskretny (analogicznie, takie techniki są używane do dźwięku). Opisane technologie są raczej trudne do zrozumienia dla zwykłego użytkownika, jednak nadal można zrozumieć niektóre ważne elementy głównych metod. Nie poruszono kwestii ustawiania monitorów, aby uzyskać obraz najwyższej jakości. W interesującej nas kwestii można jednak zauważyć, że nie zawsze konieczne jest ustalenie najwyższej możliwej rozdzielczości, ponieważ nadmierne parametry mogą prowadzić do nieprawidłowego działania urządzenia. To samo dotyczy częstotliwości odświeżania ekranu. Zaleca się używanie wartości zalecanych przez producenta lub zalecanych przez system operacyjny po zainstalowaniu odpowiednich sterowników i oprogramowania sterującego.
Jeśli chodzi o samo skanowanie lub transkodowanie informacji z jednego formatu do drugiego, powinieneś używać specjalnych programów i konwerterów, ale aby uniknąć obniżenia jakości, maksymalna możliwa kompresja w celu zmniejszenia rozmiaru plików końcowych lepiej nie dać się ponieść. Takie metody mają zastosowanie tylko w tych przypadkach, gdy informacje muszą być przechowywane na nośnikach o ograniczonej głośności (na przykład dyskach CD / DVD). Ale jeśli na dysku twardym jest wystarczająco dużo miejsca lub jeśli chcesz utworzyć prezentację do emisji na dużym ekranie lub wydrukować zdjęcia na nowoczesnym sprzęcie (drukarki fotograficzne się nie liczą), lepiej nie zaniedbać jakości.